Speech Super-Resolution (SSR) is a task of enhancing low-resolution speech signals by restoring missing high-frequency components. Conventional approaches typically reconstruct log-mel features, followed by a vocoder that generates high-resolution speech in the waveform domain. However, as log-mel features lack phase information, this can result in performance degradation during the reconstruction phase. Motivated by recent advances with Selective State Spaces Models (SSMs), we propose a method, referred to as Wave-U-Mamba that directly performs SSR in time domain. In our comparative study, including models such as WSRGlow, NU-Wave 2, and AudioSR, Wave-U-Mamba demonstrates superior performance, achieving the lowest Log-Spectral Distance (LSD) across various low-resolution sampling rates, ranging from 8 kHz to 24 kHz. Additionally, subjective human evaluations, scored using Mean Opinion Score (MOS) reveal that our method produces SSR with natural and human-like quality. Furthermore, Wave-U-Mamba achieves these results while generating high-resolution speech over nine times faster than baseline models on a single A100 GPU, with parameter sizes less than 2% of those in the baseline models.
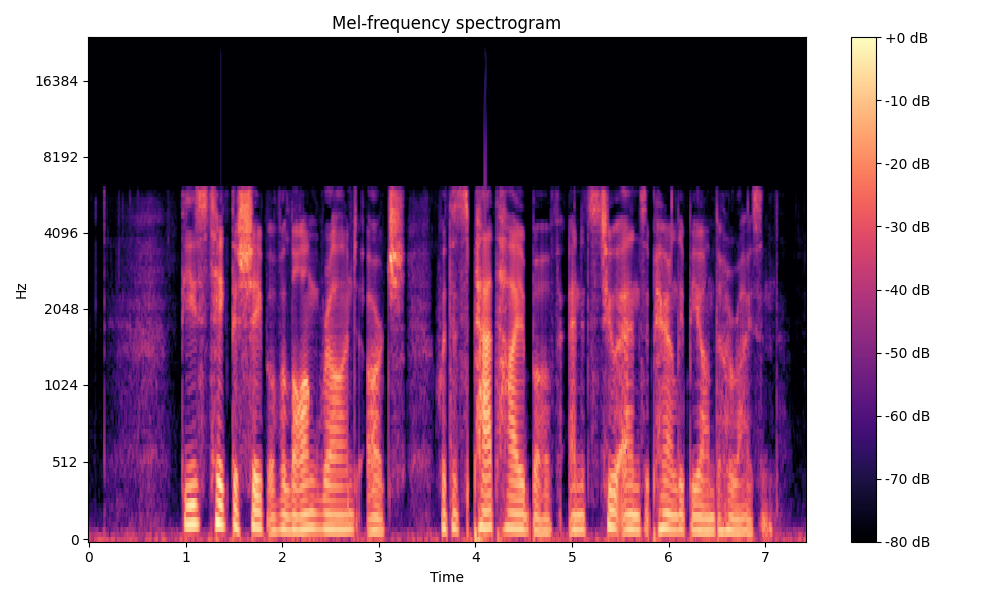
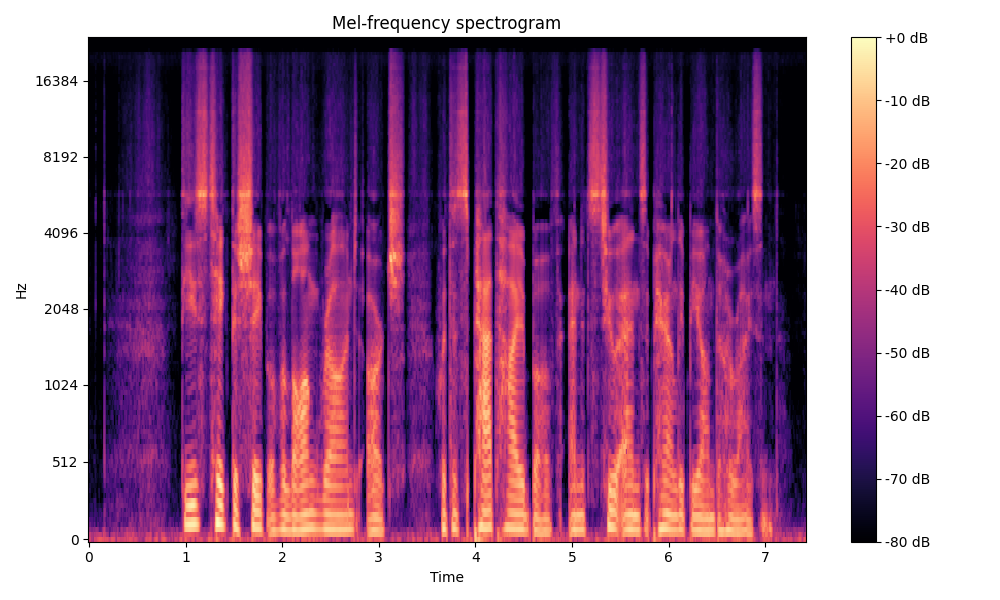
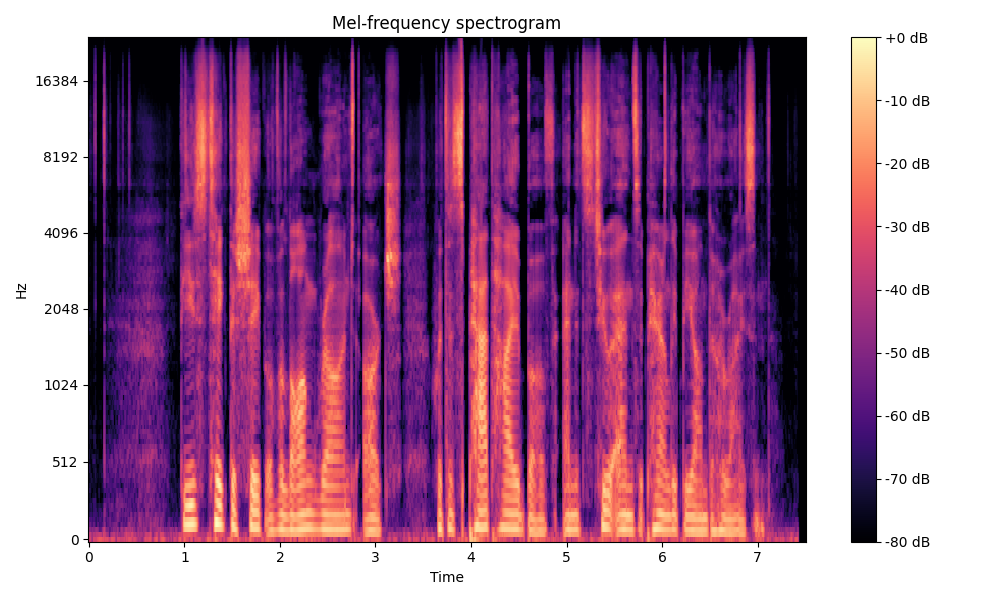
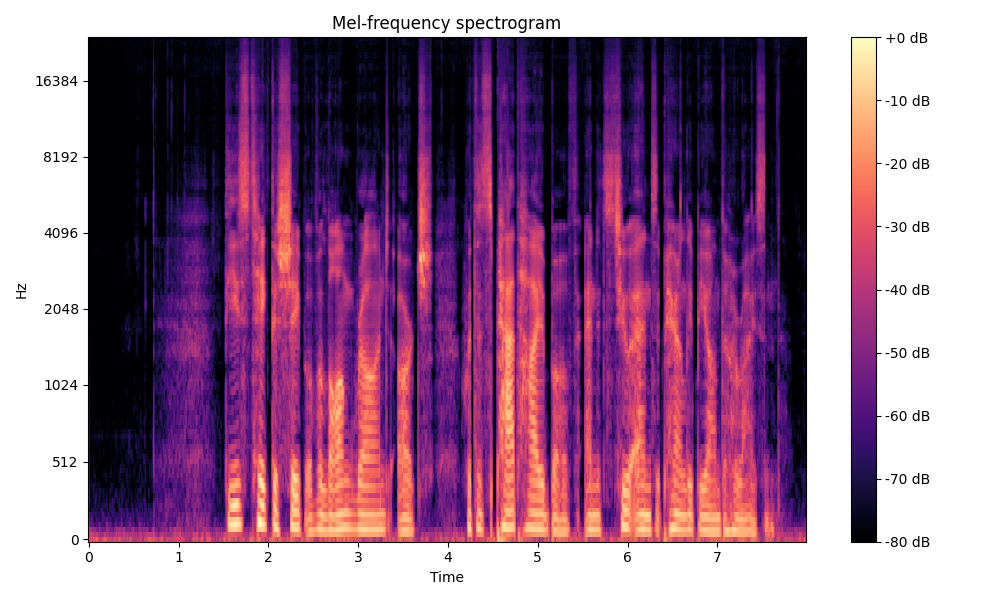
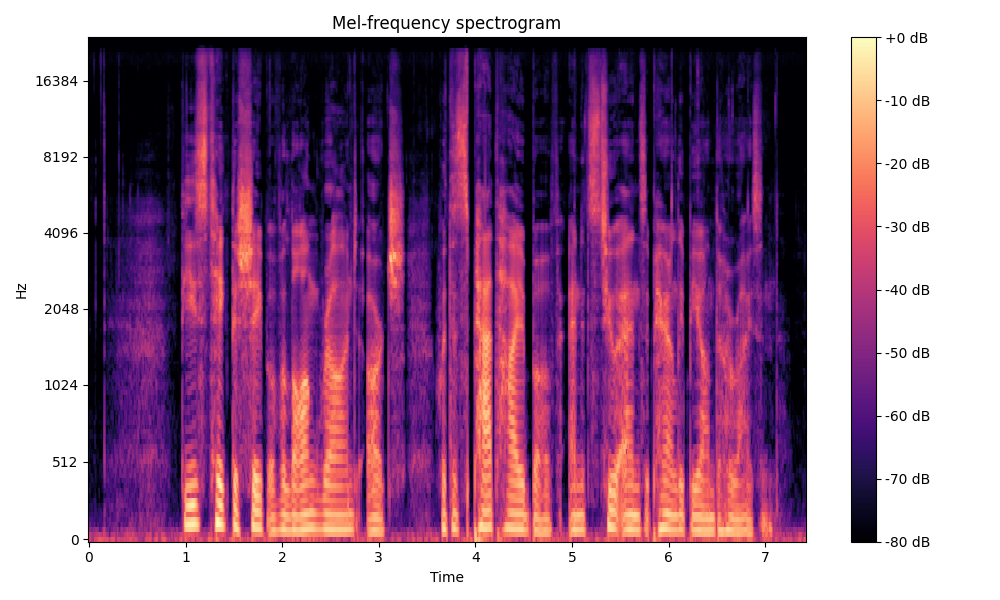
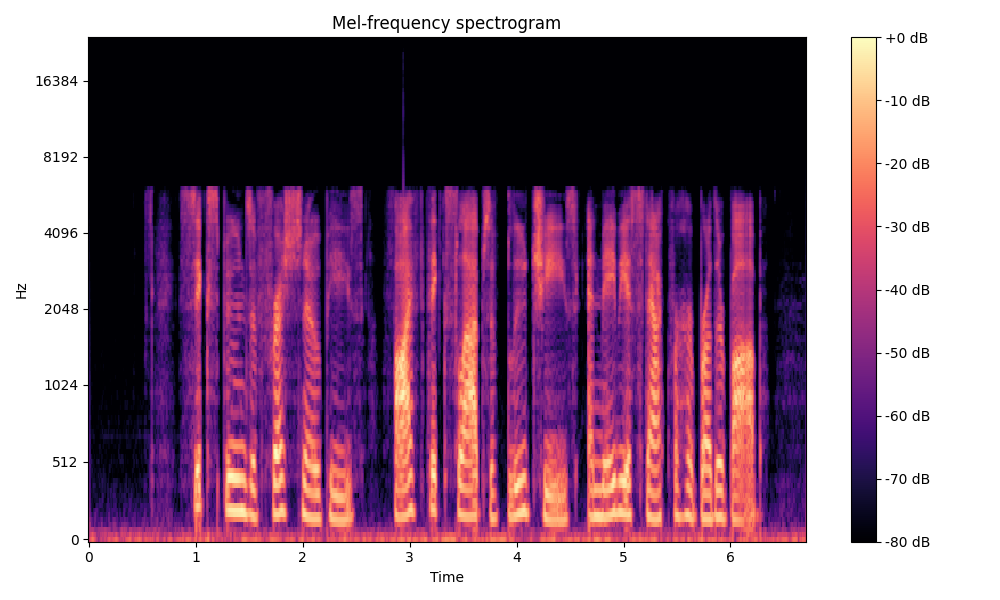
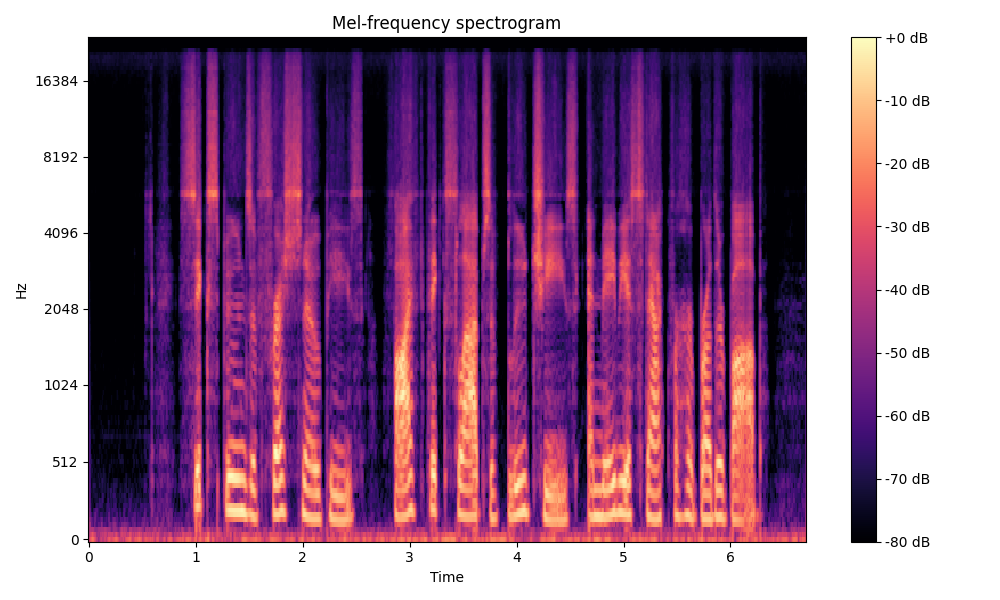
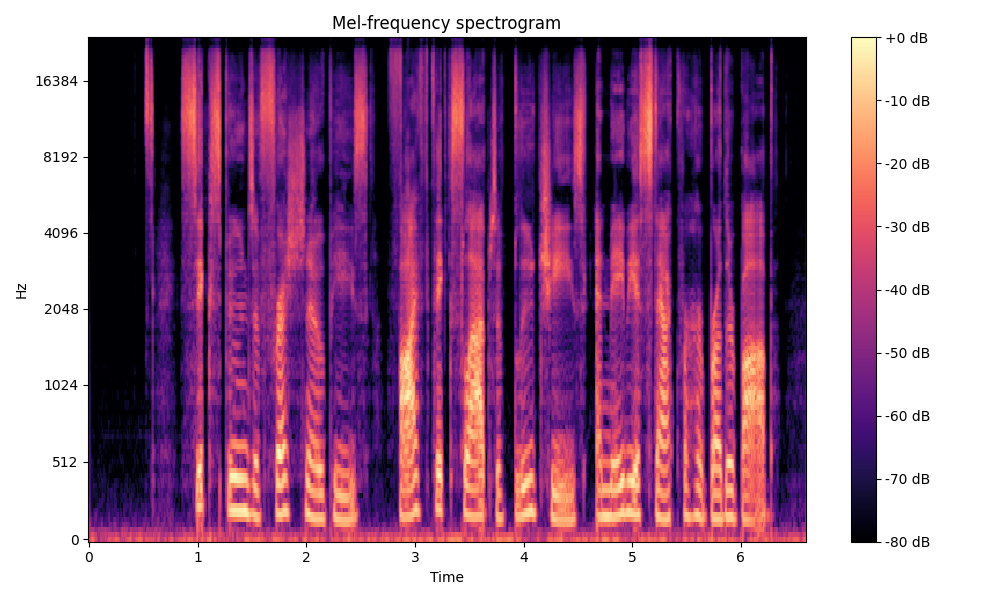
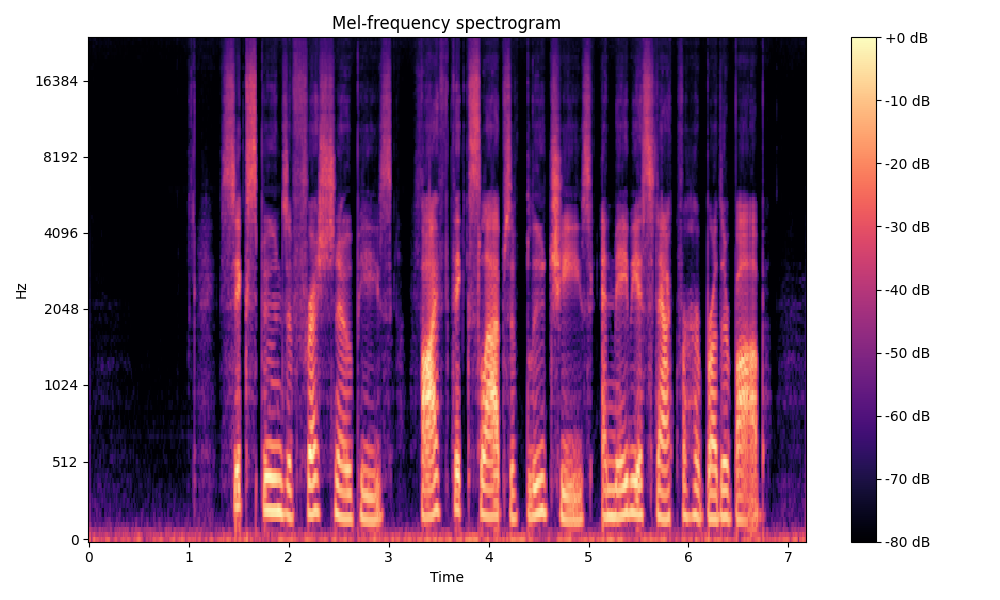
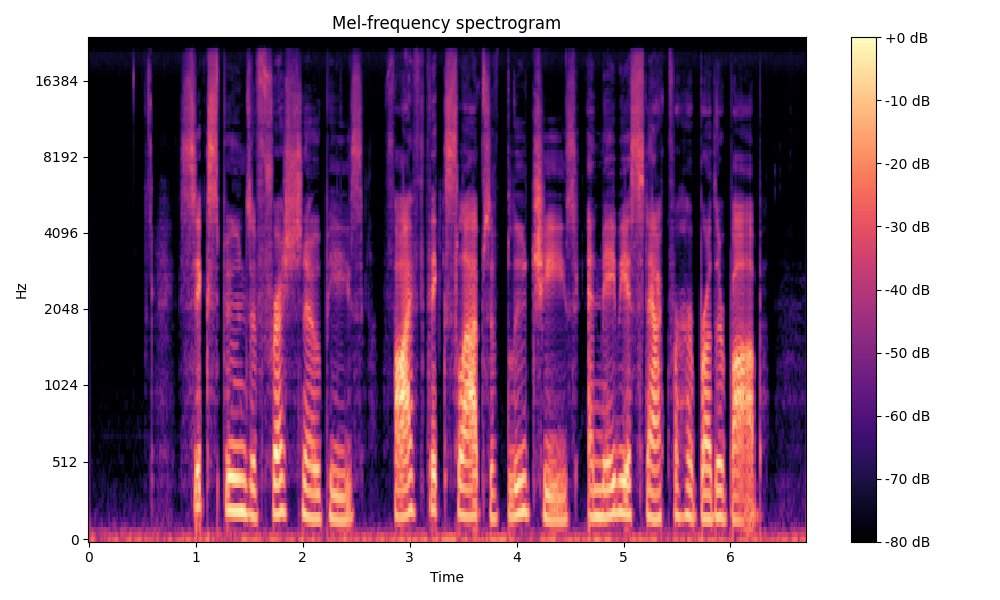
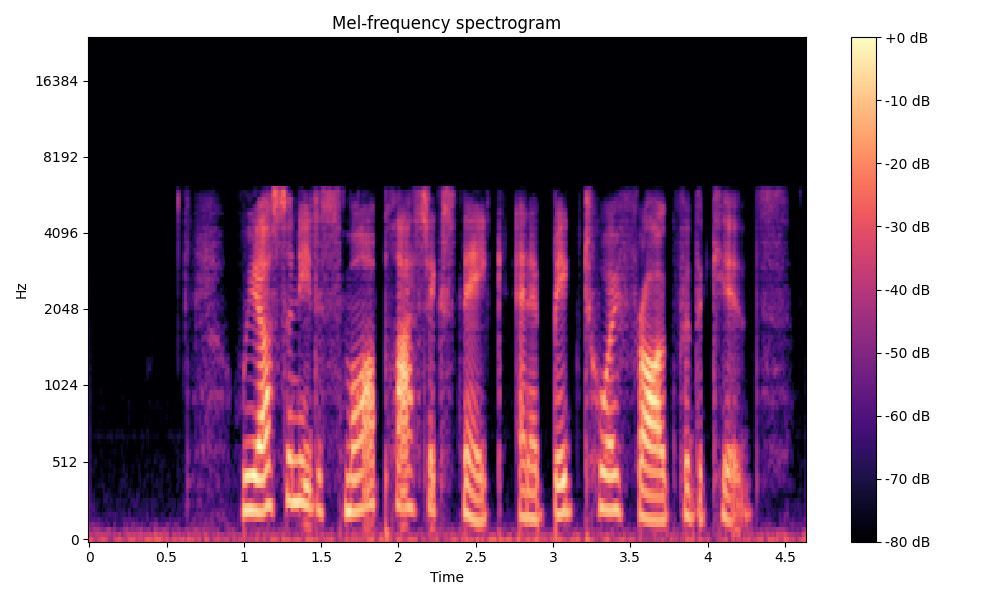
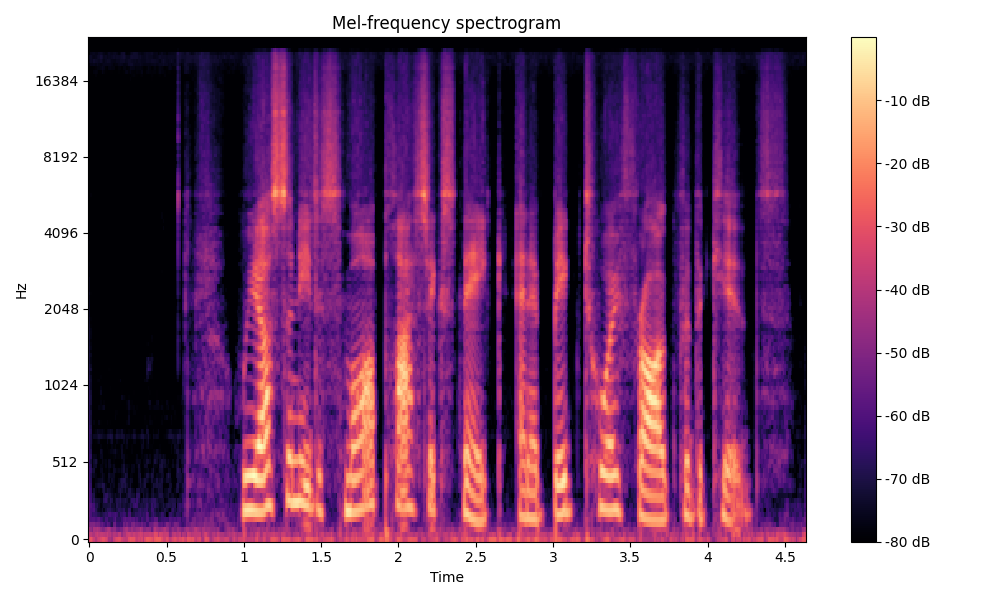
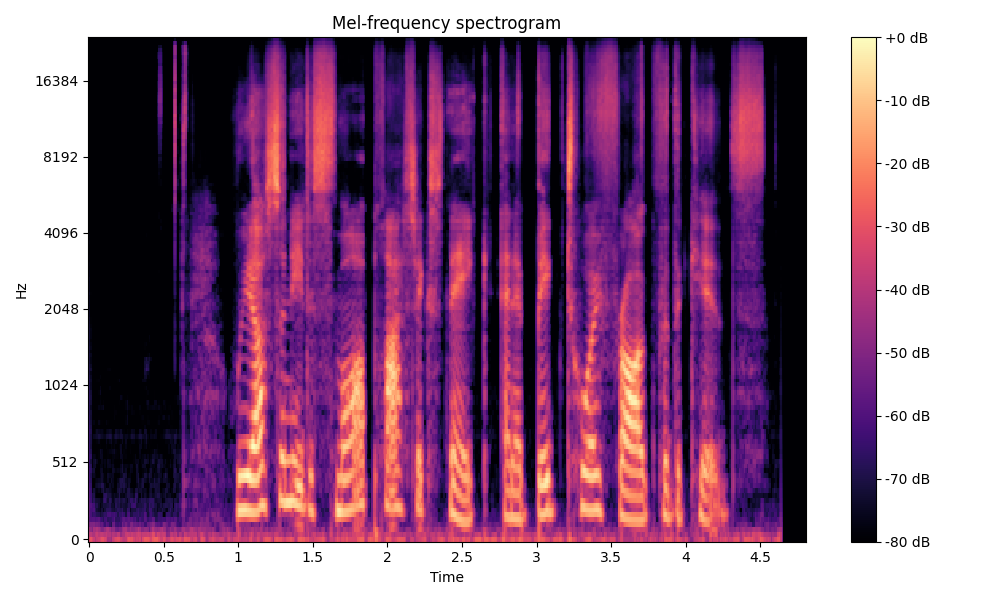
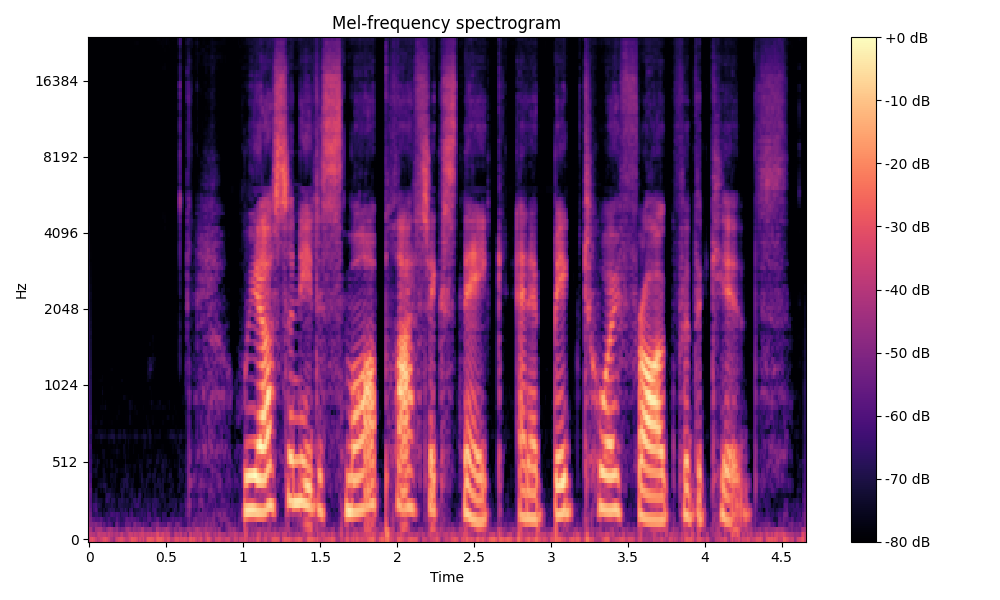
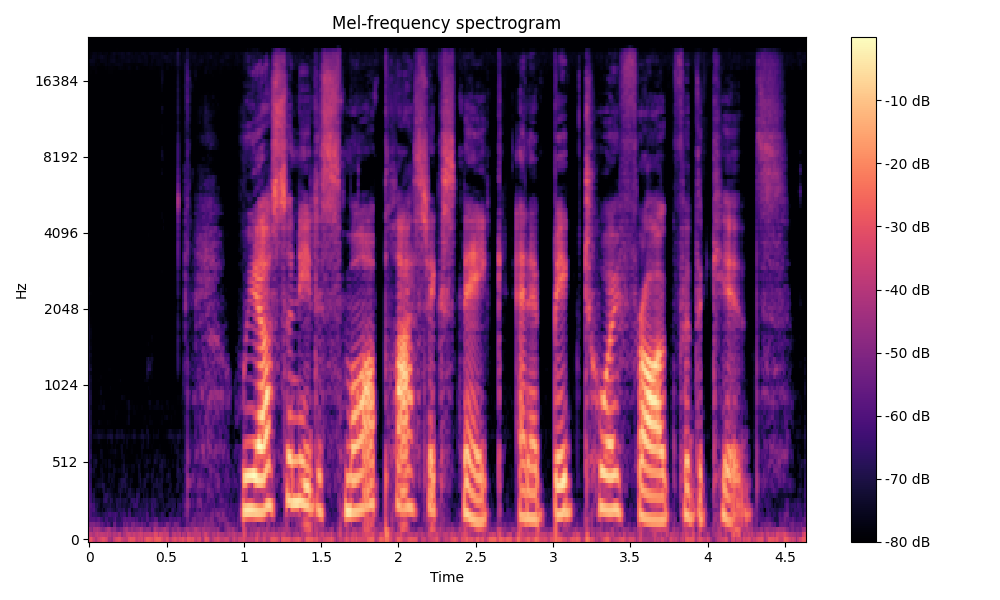
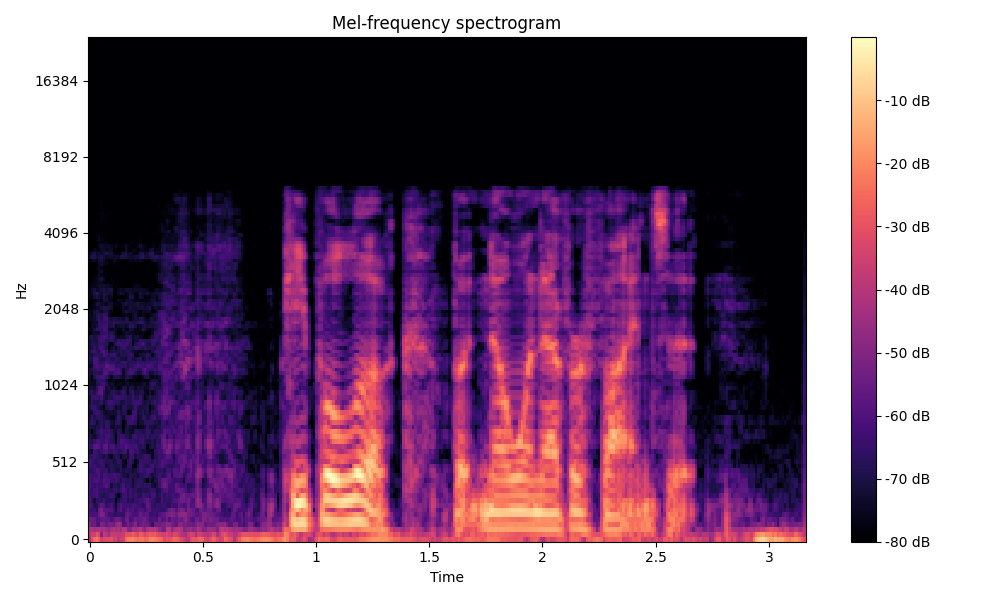
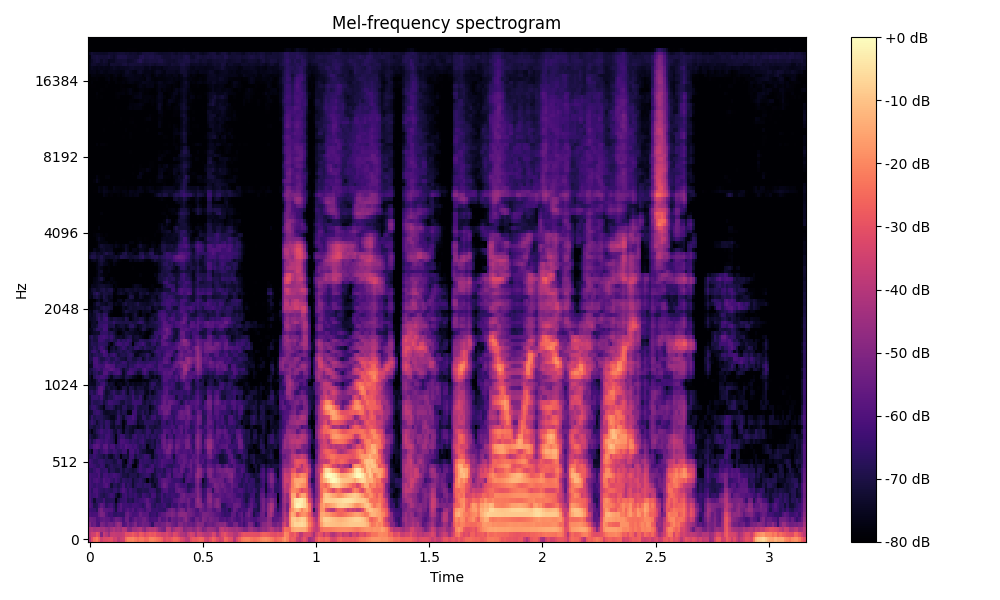
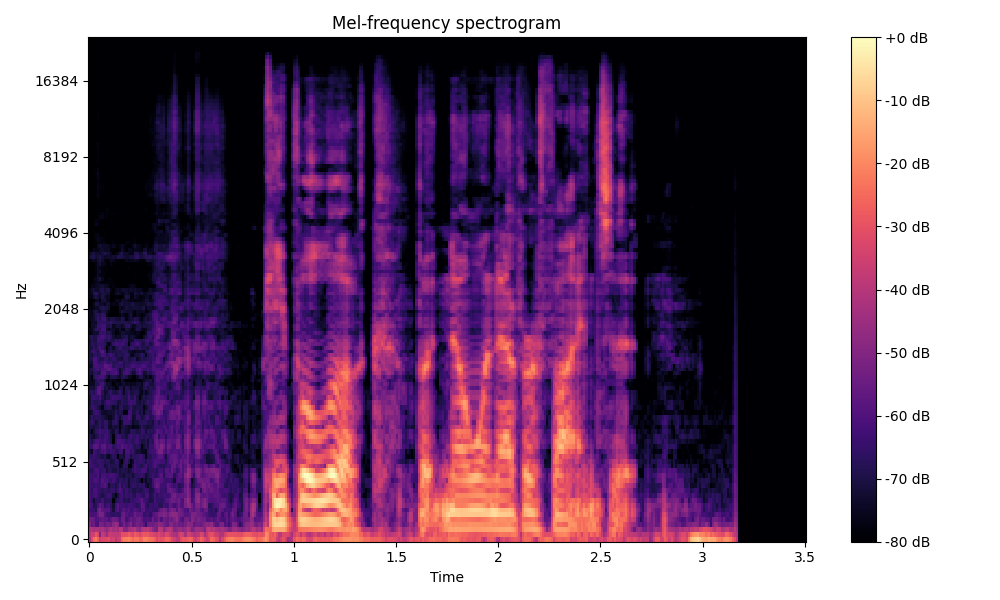
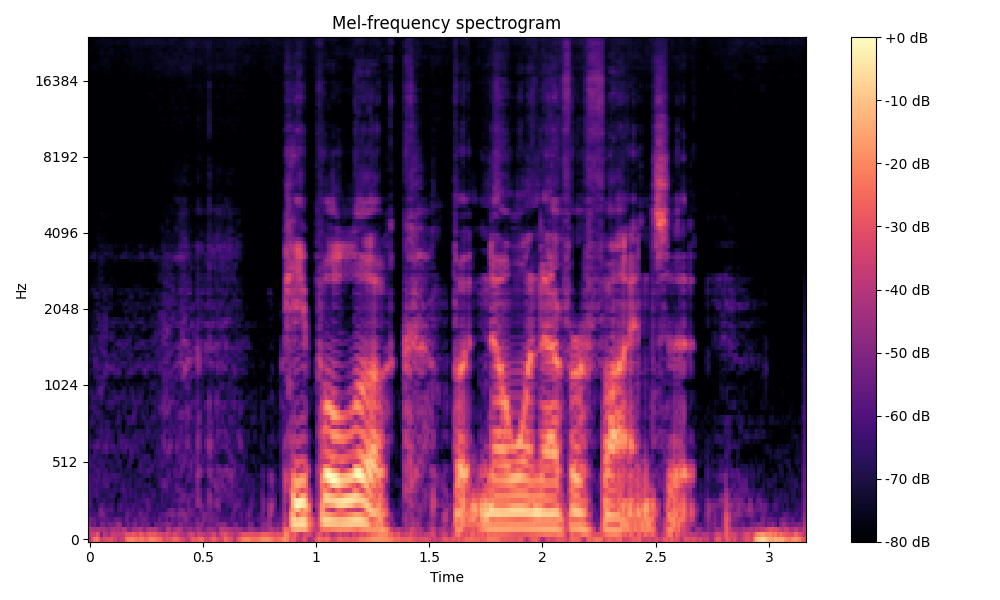
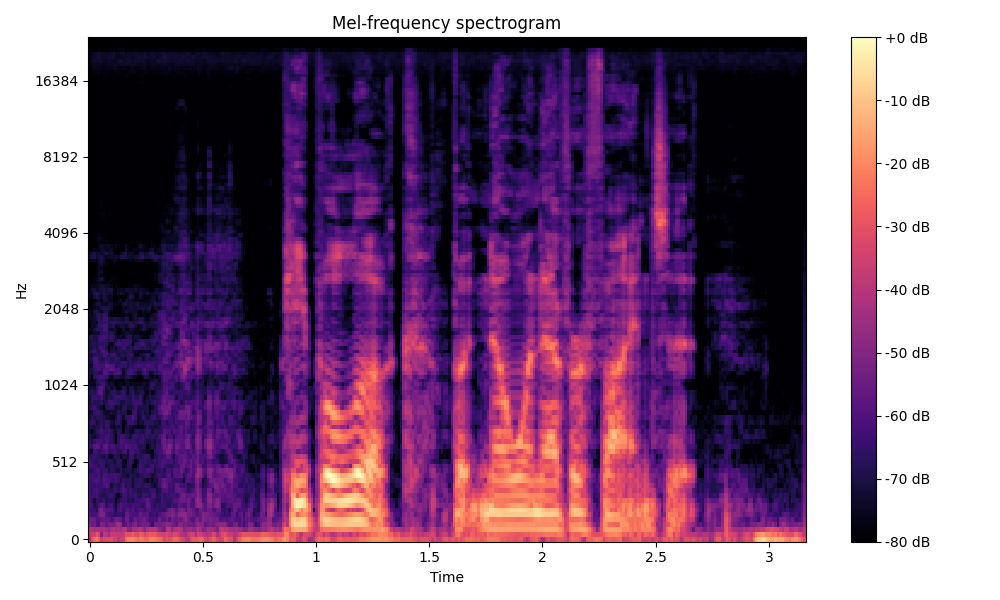
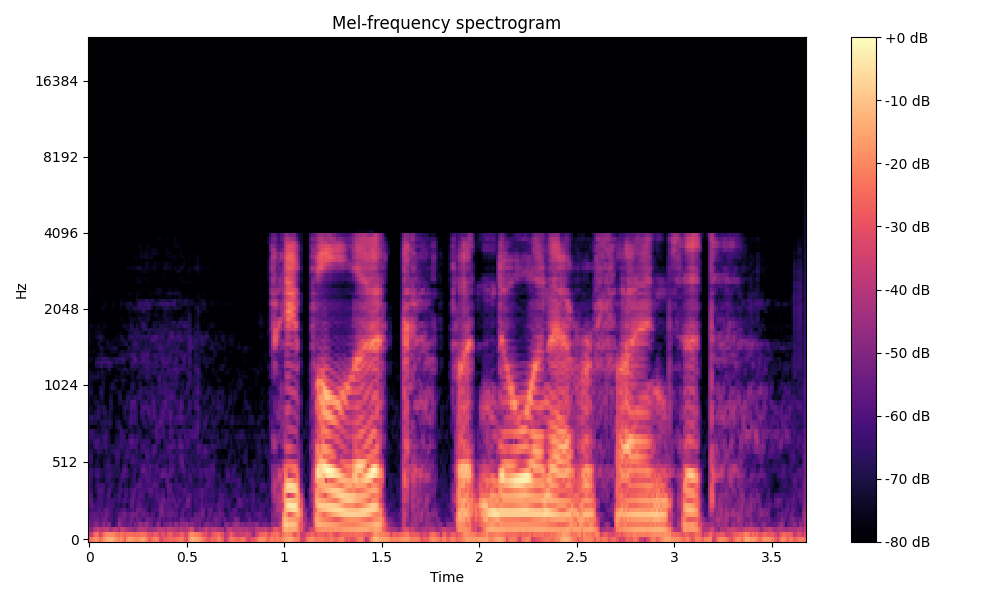
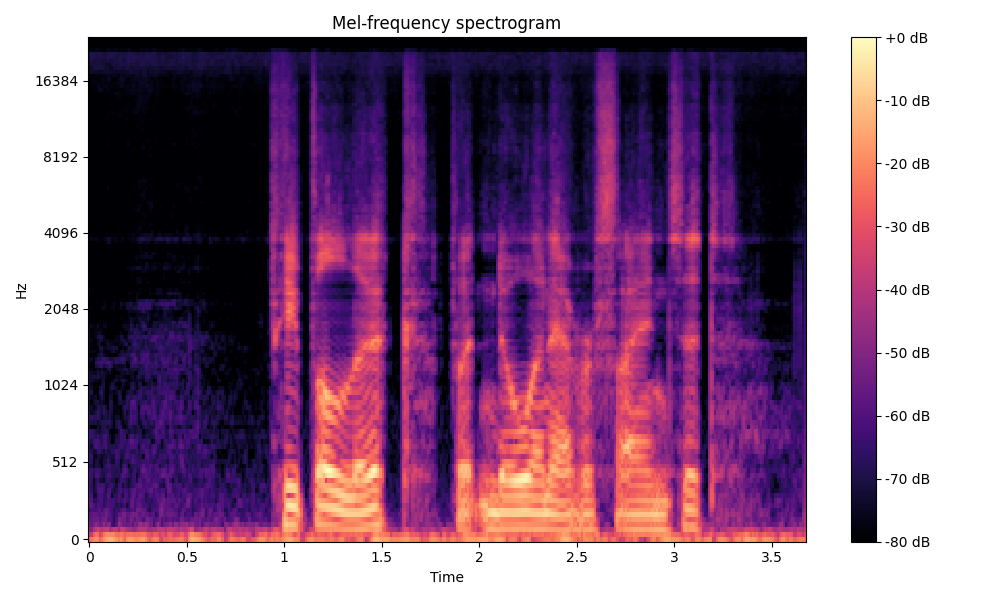
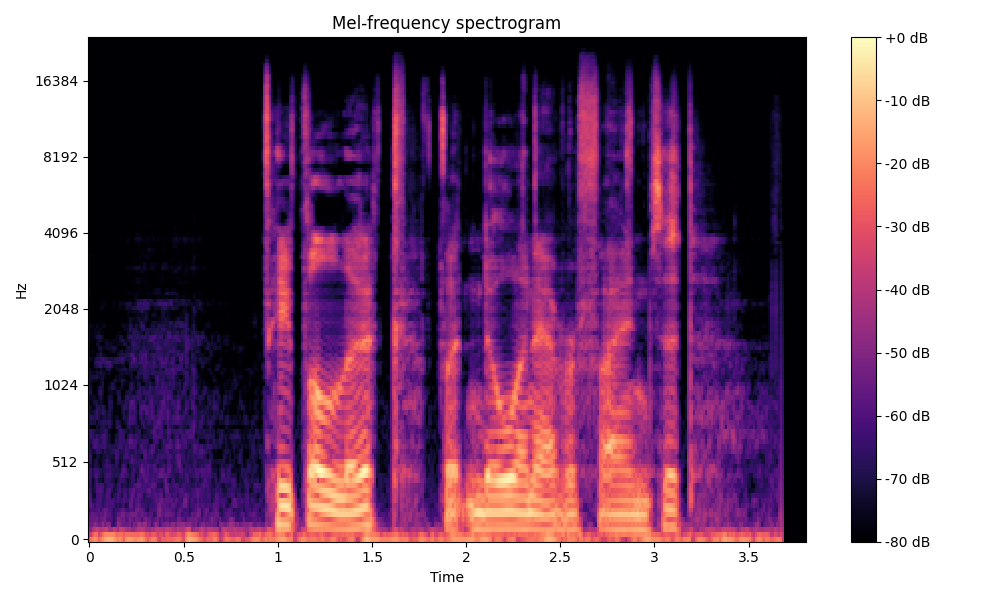
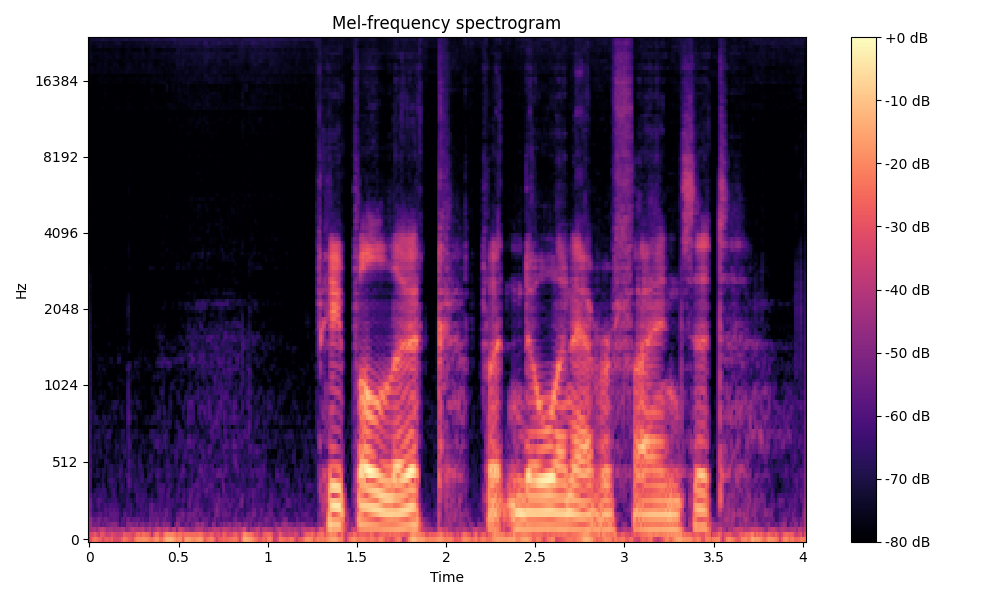
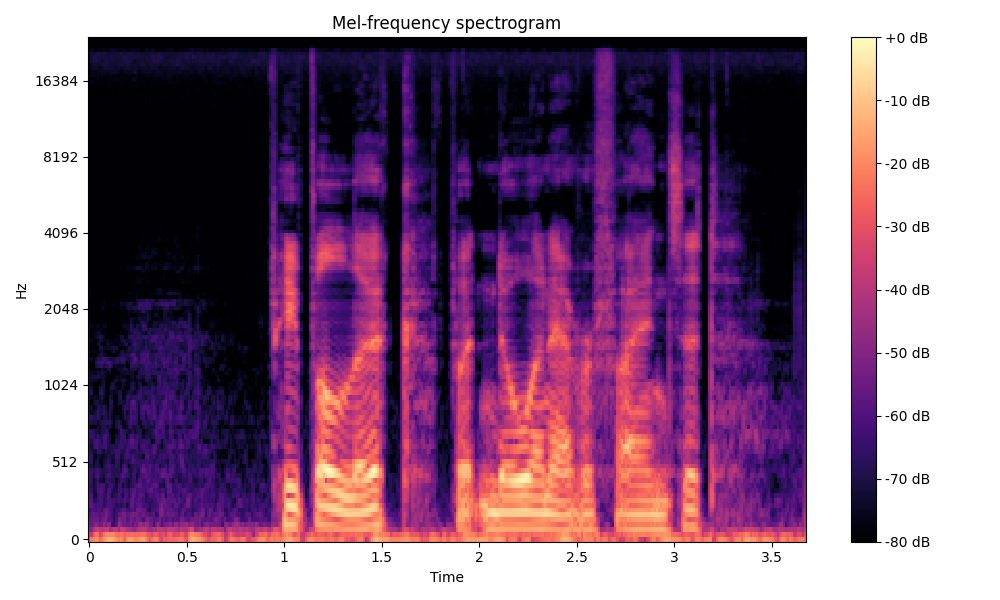
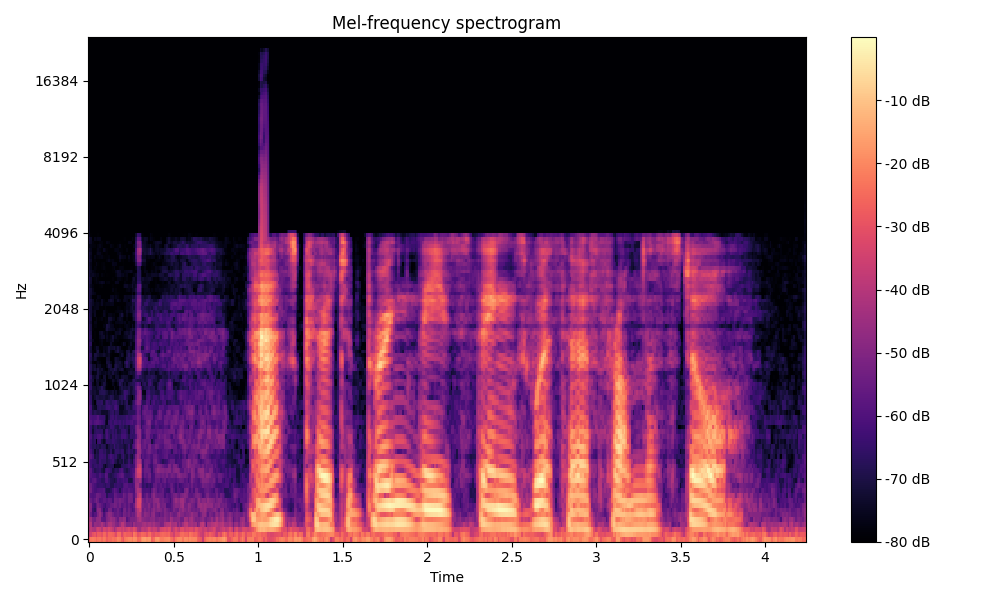
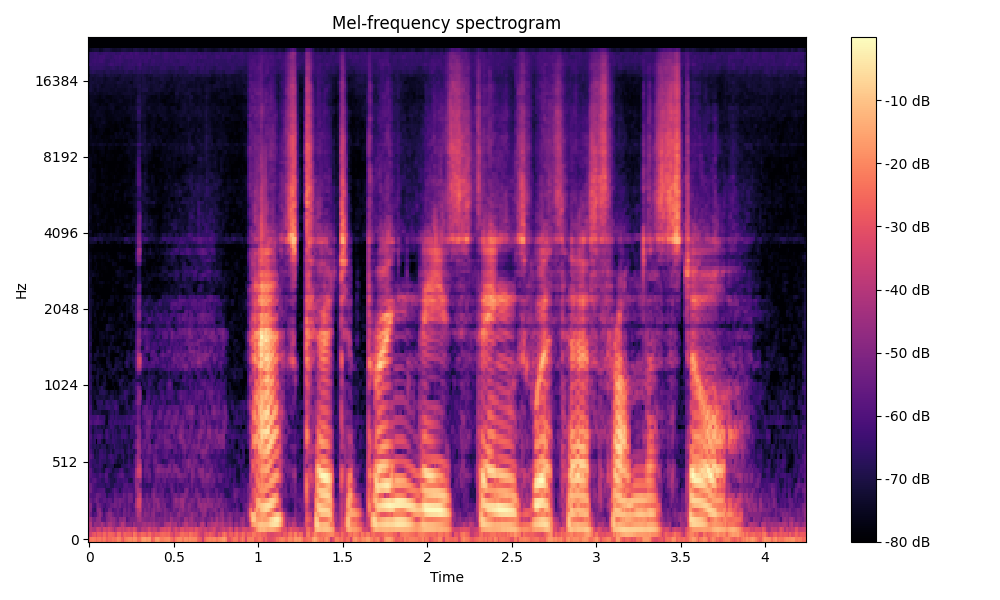
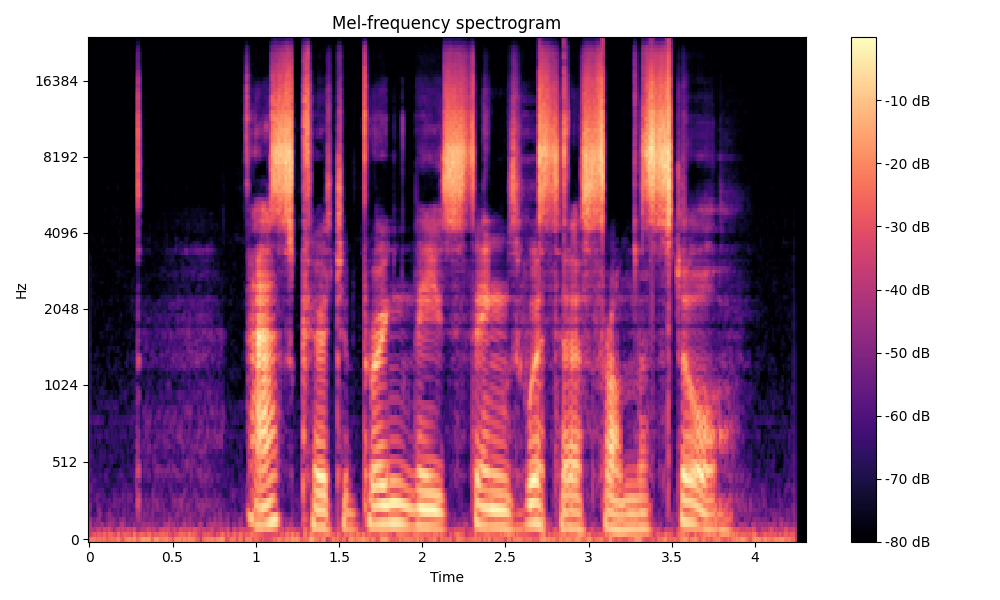
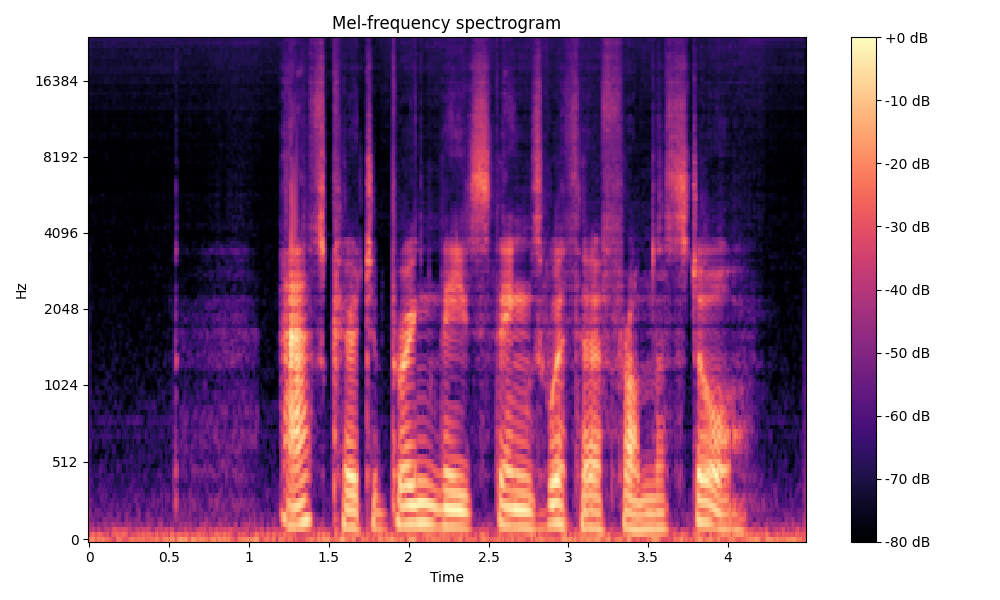
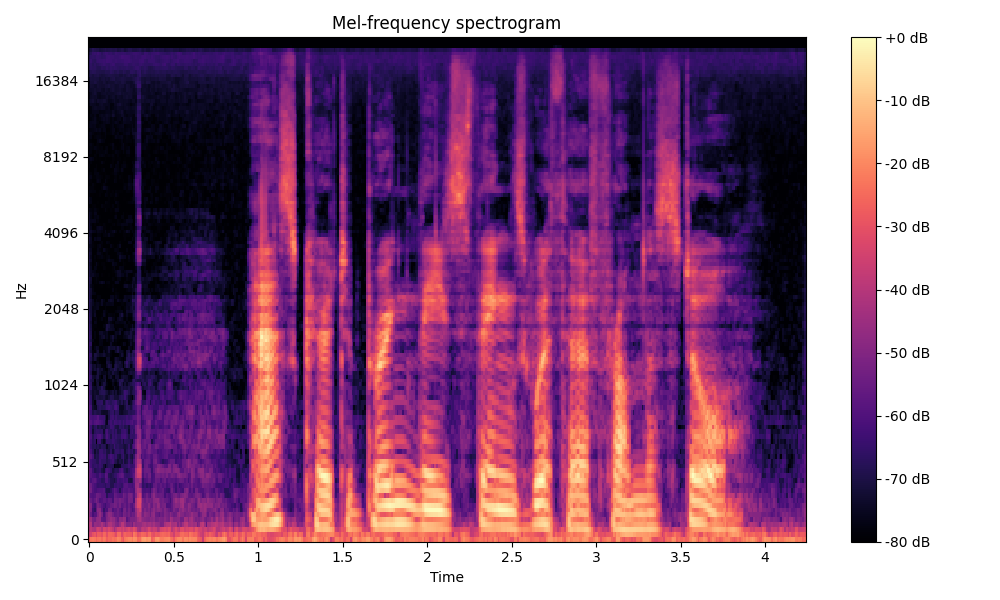
Comparisons of the super-resolved speech waveforms with State-of-the-Art (SOTA) models on some data files from VCTK-Test.
Ground Truth LR refers to the low-resolution (LR) signal that has sampling rates of either 12 kHz or 8 kHz.
Ground Truth HR refers to the high-resolution (HR) signal that has sampling rates of 48 kHz. This is our target speech.
All waveforms were volume-normalized to ensure the equivalence of other conditions.
All spectrograms are time-frequency representations with mel-frequency as the y-axis.